



Compound Intelligence
Knowledge and judgment in VC has historically lived in the minds of individual investors. We're building an AI stack for our firm that changes that.
This year coding agents inverted the traditional dynamic of software development: instead of each feature making the next one harder, each feature makes the next one easier, because learnings get codified back into the system. Termed Compound Engineering, this idea extends far beyond writing code.
Applied to an investment firm, it creates a knowledge flywheel: we build data infrastructure to make agents useful; agents automate workflows and generate structured output; that output feeds a growing institutional knowledge base; and richer knowledge makes every agent, workflow, and decision better. We call it compound intelligence.
We’ve spent the last two years rebuilding how BCAP operates around AI -- new data infrastructure, custom software, and close iteration with our engineering team across every part of our process, from sourcing to portfolio management. Here's how we're doing it and what we've learned.
How we’re building it
Systems of record and AI-readiness
Implementing an AI stack is first and foremost a data problem. Most venture firms run on information spread across siloed SaaS tools. It's not uncommon for every department to have its own CRM or tracking tool. After trying to point agents at our CRMs, we found out the hard way that most SaaS tools are designed for humans clicking through a UI, not agents reasoning over structured data.
To get full value out of an AI stack, agents need easy access to your full knowledge base. If critical data lives in a system that agents can't query and write back to, it has to be upgraded or replaced, otherwise that data is invisible to your stack.
We audited every system of record for two things: how expressively agents can read the data (filter, sort, join across entities), and whether agents can write back (create records, update fields, trigger workflows). That produced three tiers:
- Structured query access: Direct database access, warehouse connector, or data lake mirror. Agents can express arbitrary queries against the full schema. The data stays where it is and agents reach in directly. Best case.
- Full-featured API: Complete CRUD with structured filtering, sorting, and pagination. Rich enough that agents can compose the queries they need rather than being limited to whatever endpoints a vendor chose to expose. Workable, but the gap between a well-designed API and a mediocre one is large. Each tool requires its own evaluation.
- Opaque: UI-first. Programmatic access unavailable or very limited. Functionally unusable for agent integration without scraping or manual export.
Tier 1 tools earned their place — agents reach in directly and the data stays where it is. Tier 3 tools are obsolete; we're migrating or rebuilding. Tier 2 is case-by-case: some vendors integrate without a headache, others require workarounds that make them too burdensome. We're building our own version of at least one Tier 2 CRM because we want to own our data and control how it flows downstream.
Org-native apps
This removes the constraints of generic software. We used to accept “good enough”; now the bar is “perfect for us specifically.”
For example, we used to run investment committee votes as Slack polls and manually record decisions and next steps in a deals CRM. We're now building a custom app that handles all deal CRM responsibilities and automatically captures every decision-related data point as it's created at each stage of our process. Our team sees a better interface than before, and the backend is far richer, enabling us to measure things like decision quality and process quality over time. It's only at MVP stage, but it's already a clear improvement over our old generic CRM because it's built around our exact workflow — and every data point it captures feeds future agent capabilities.
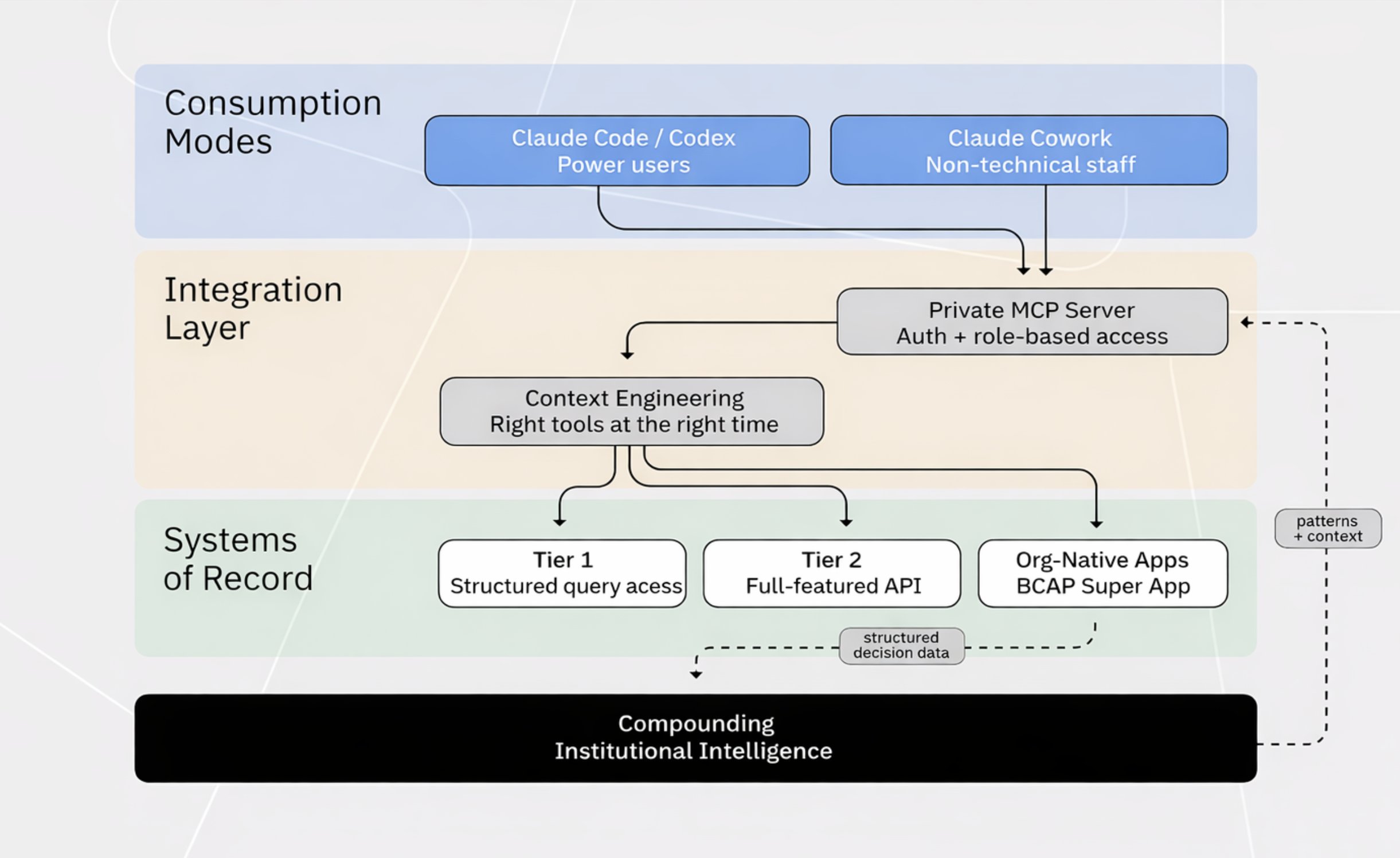
The integration layer
The next ingredient is an agent-accessible interface (e.g. MCP, API, or CLI) engineered to deliver the right context at the right time. We built a private MCP server that bundles all of our systems of record behind a single integration point. Authenticate via OAuth, and your agent has role-based access to everything you'd normally log into a vendor to see. When we add a new data source, everyone gets it at once without any individual setup.
Here's what this looks like in practice. An investor types: "Prepare a meeting brief for alice@newLP.com." The agent recognizes the skill, extracts the domain, and fires off ~12 tool calls in parallel -- seven hit our CRM via SQL queries to Databricks (account info, contacts, fund commitments, meeting history, email threads), two pull interaction history for specific attendees, and three run web research through an Exa API dispatcher for firm background and attendee bios. All 12 calls execute simultaneously, finishing in seconds. The agent synthesizes everything into a formatted brief: firm overview, relationship history, meeting goals, attendee bios. What used to take hours of manual prep across multiple tabs now takes minutes.
Making this work well is a context engineering problem. Early on, we exposed every tool directly and the model started picking the wrong ones. The fix was layered exposure: our web research API, for instance, presents two tools to the agent (a tool list and a dispatcher) instead of seven individual endpoints. The agent picks the category, then the dispatcher routes to the right tool. The CRM tools stay individual because parallel execution across distinct queries is the primary use case. The principle is the same either way -- the agent only sees what's relevant to its current task.
How the team uses it
Individual preferences and levels of technical expertise differ across our team, so there is no one size fits all harness for interacting with our AI stack. Our MCP infrastructure serves two distinct user populations with different interfaces.
Power users run Claude Code, Codex, or custom harnesses. They maintain personal memory and context files and tool stacks tailored to their workflows. Those often don’t belong in a company-wide tool, and with our integration layer, they evolve alongside shared company MCP servers.
We've found that experimentation on personal setups regularly produces skills and automations useful enough to roll out broadly. A team member built a memo skill that generates high-quality, visually polished memos from data room materials — these now get shared with the entire organization for investment committee meetings. We also maintain a shared GitHub repository of reusable skills built specifically for our systems of record.
Non-technical and operational staff prefer desktop apps. Claude Cowork has been particularly effective here. It provides a structured, guided environment for interacting with coding agents that feels like a standard AI chat interface, but with full access to our MCP integration and shared team skills uploaded from GitHub.
The harnesses will change, but the data layer and integrations underneath them won’t, and that’s where the flywheel lives.
Where this leads
Parts of this are already running. Others are weeks or months away. Here is what a day looks like when the full system is in place:
- Morning. You sit down to a briefing with a summary of everyone you're meeting today and everything your agents did overnight. Your sourcing agent flagged something of note: a researcher at a major tech company just published work that maps directly onto a gap in your investment thesis. She's connected to two of your portfolio founders. You didn't ask the agent to find her; it connected the dots across your thesis, your relationship graph, and a public signal, and surfaced the match because it was too strong to ignore. You ask one of your mutuals for a warm intro.
- IC meeting. The team sits down after reviewing agent-prepared diligence memos, each with deep supporting market research, competitive analysis, and team assessment. The conversation immediately focuses around key assumptions needed to get excited about the business, not summaries of what they do. Today, the system flagged that the last time your firm saw a deal with this exact growth profile, you passed and it became a category winner. That data point helps the deal lead build support for another meeting.
- Late afternoon. A monitoring agent cross-referenced recent news and flagged that three of a portfolio company's largest customers announced cost-cutting initiatives in the last month. Before you pick up the phone, you ask the system to pull comparable situations from across the portfolio — which companies faced similar concentration risk, what worked, who you could introduce. Instead of spending thirty minutes bringing you up to speed, the CEO gets a thought partner who shows up with a playbook informed by the firm’s past experience.
- End of day. Every signal discussed in IC, every argument made, every vote and its reasoning gets structured and wired into the knowledge graph, becoming additional context for the next decision.
What does this mean for VC firms?
Investment firms think about compounding primarily in terms of capital. Increasingly, they will think about it in terms of intelligence. Firms that build systems to compound intelligence will make better decisions, improve hit rates, and accumulate durable institutional memory.
The most immediate effect of this shift is operational leverage. Mechanical workflows that once constrained capacity are being automated, allowing teams to spend more time on judgment, relationships, and decision-making. A small team can operate with the throughput of a much larger one; We’re already running workflows that would have required additional headcount two years ago. Over time, AI-native VC firms should be able to manage far more capital without scaling headcount proportionally.
The more important effect is the creation of capabilities that didn’t previously exist. Agentic systems make it possible to build new engines for sourcing, diligence, research, and pattern recognition. They can ingest and surface signal across vast, fragmented datasets in ways that materially expand how firms generate edge in private markets.
The deepest shift, though, is in how institutional knowledge compounds. Venture firms have historically depended on individual investors carrying judgment in their heads, which means that when a senior partner leaves, much of the firm’s accumulated pattern recognition leaves with them. AI-native systems change that. Every deal reviewed, every IC debate, and every portfolio outcome can be captured, structured, and fed back into the firm’s decision-making process. Over time, knowledge stops residing primarily in individuals and starts compounding at the level of the institution.
Blockchain Capital is an investor in one or more of the protocols, companies or entities mentioned above. The views expressed in this article may be the personal views of the author and do not necessarily reflect the views of Blockchain Capital and its affiliates. Neither Blockchain Capital nor the author guarantees the accuracy, adequacy or completeness of information provided this article. No representation or warranty, express or implied, is made or given by or on behalf of Blockchain Capital, the author or any other person as to the accuracy and completeness or fairness of the information contained in this article and no responsibility or liability is accepted for any such information. Nothing contained in this article constitutes investment, regulatory, legal, compliance or tax or other advice nor is it to be relied on in making an investment decision. This article should not be viewed as current or past recommendations or solicitations of an offer to buy or sell any securities or to adopt any investment strategy. This article may contain projections or other forward-looking statements, which are based on beliefs, assumptions and expectations that may change as a result of many possible events or factors. If a change occurs, actual results may vary materially from those expressed in the forward-looking statements. All forward-looking statements speak only as of the date such statements are made, and neither Blockchain Capital nor each author assumes any duty to update such statements except as required by law. To the extent that any documents, presentations or other materials produced, published or otherwise distributed by Blockchain Capital are referenced this article, such materials should be read with careful attention to any disclaimers provided therein.


.png)

.png)
.png)




No Results Found.